
Machine learning algorithms have recently been used on social media to create “bot-generated” images and sentences. One fun aspect of this generated work is that the tone of the original work tends to shine through, despite the fact that the generated work is often a jumble of conceptually unrelated words.
A great example of generated content is /r/SubredditSimulator, which is an online forum populated entirely by bots creating nonsensical posts.
I wanted to experiment with these machine learning tools and generate something interesting, but I also wanted to use machine learning to capture a tone that was instantly recognizable. At the time, I had been playing Dark Souls, and the item descriptions in that game immediately came to mind. The text of Dark Souls is evocative and esoteric, and I thought it would be interesting (and potentially humorous) to see whether a machine-learning algorithm could imitate those qualities.

Environment Setup
After a brief investigation, I found a Python module that closely aligned with my goals: textgenrnn. This module requires TensorFlow as a prerequisite, so I installed the latest version of TensorFlow in a Python virtual environment (or “venv”).
I also knew that I was going to be training this model from scratch, and that training machine learning models is a computationally intensive task. Rather than rely on my CPU, I decided to leverage the parallel processing power of my GPU. Instructions on how to configure a GPU for use with TensorFlow can be found here.
I configured everything to get all these pieces working nicely together. I also had to avoid some bugs in these libraries:
- Use a version of Python supported by TensorFlow
- Use a version of CUDA supported by TensorFlow
- Install cuDNN (install guide)
- Install textgenrnn from source instead of from a package manager (GitHub issue)
- Set some TensorFlow settings at the start of my script (GitHub issue)
After completing all these steps, I had an environment that could run textgenrnn and leverage my GPU’s processing power. To test out my environment, I used the Python console to complete the first example provided by the textgenrnn documentation:
Python 3.9.7 (tags/v3.9.7:1016ef3, Aug 30 2021, 20:19:38) [MSC v.1929 64 bit (AMD64)] on win32
> from textgenrnn import textgenrnn
> textgen = textgenrnn()
2021-12-20 13:30:59.446801: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-12-20 13:30:59.874784: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1525] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 6005 MB memory: -> device: 0, name: NVIDIA GeForce RTX 2070, pci bus id: 0000:01:00.0, compute capability: 7.5
> textgen.generate()
2021-12-20 13:31:07.501109: I tensorflow/stream_executor/cuda/cuda_dnn.cc:366] Loaded cuDNN version 8100
Was being a train at a study finally app on the English in the money, and they am I lost here and any of you guys have a positive.
It looks like we’re now able to generate nonsensical sentences with the help of my GPU and textgenrnn’s default model. The next step is to use the Dark Souls item descriptions to train our own model.
Training Data
The first step in training a machine learning model is to gather training data (our “corpus"). This corpus is what the model will “learn” from and will inform what the model chooses to output.
In our case, we’d like to extract every item description from Dark Souls and use those item descriptions as our training data. This task can be accomplished by using modding tools that were created by members of the Dark Souls modding community. Here are the steps I followed to extract the data from an unmodified PC copy of Dark Souls: Prepare to Die Edition:
- Download UnpackDarkSoulsForModding
- Unpack the Dark Souls files with UnpackDarkSoulsForModding
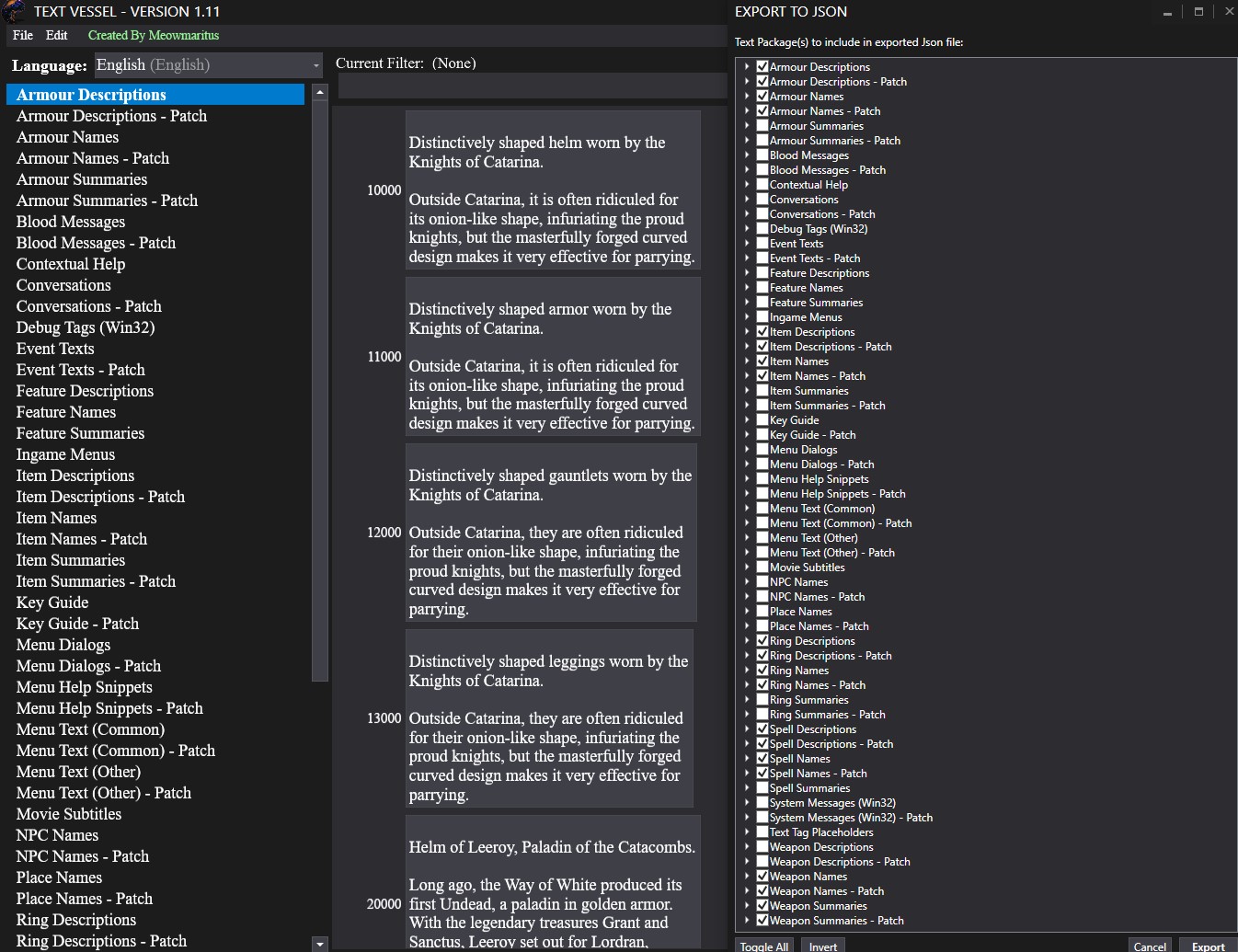
- Download TextVessel
- Open TextVessel and select the directory containing the unpacked Dark Souls files
- In TextVessel, select File > Export JSON File and select the following categories, both with and without the “_Patch” suffix:
- ArmourNames
- ArmourDescriptions
- ItemNames
- ItemDescriptions
- RingNames
- RingDescriptions
- SpellNames
- SpellDescriptions
- WeaponNames
- WeaponDescriptions
- Click “Export” to create a JSON file containing the selected data
At this point, we have an exported JSON file containing the names and descriptions of all the items in the game. However, there are two problems with this JSON file:
- It contains “<null>” entries that need to be removed
- Item names and descriptions are not related to each other
We’ll write a module that loads this JSON file and does some preprocessing to filter out the null entries and prepend each item’s name to its corresponding description. Packages like TensorFlow make Python one of the leading languages for machine learning research, so we’ll use Python for this task.
"""
Responsible for parsing the JSON export from the game into
an array of strings (corpus). This corpus can then be used
to train a text generation model.
"""
import json
import os
NAME_DESCRIPTION_MAPPING = {
"ArmourNames": "ArmourDescriptions",
"ArmourNames_Patch": "ArmourDescriptions_Patch",
"ItemNames": "ItemDescriptions",
"ItemNames_Patch": "ItemDescriptions_Patch",
"RingNames": "RingDescriptions",
"RingNames_Patch": "RingDescriptions_Patch",
"SpellNames": "SpellDescriptions",
"SpellNames_Patch": "SpellDescriptions_Patch",
"WeaponNames": "WeaponDescriptions",
"WeaponNames_Patch": "WeaponDescriptions_Patch"
}
# read the entire JSON file into a single Python dictionary called exportObj
exportPath = os.path.join(os.path.dirname(__file__), 'export.json')
with open(exportPath, 'r') as exportFile:
data = exportFile.read()
exportObj = json.loads(data)
corpus = [] # the "corpus" array will be the main export from this module
for namesKey, descriptionsKey in NAME_DESCRIPTION_MAPPING.items():
names = exportObj[namesKey]
descriptions = exportObj[descriptionsKey]
# map each item's name to its corresponding description
for itemId, description in descriptions.items():
# filter out any data where the description is missing or "<null>"
if description is not None and description != "<null>" and itemId in names:
name = names[itemId]
corpus.append("\n".join([name, description]))
This file is saved in my project as corpus.py. With that, we have our training data, and we’re ready to start training the model.
Model
We’ll start our Python script by importing our required modules and configuring some TensorFlow settings:
import tensorflow as tf
from textgenrnn import textgenrnn
import os
from corpus import corpus
# configure TensorFlow settings
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True # https://github.com/tensorflow/tensorflow/issues/24496
session = tf.compat.v1.InteractiveSession(config=config)
We’d like to avoid having to recompute the model every time we want to generate new text from it. To that end, we’ll check whether files describing a model already exist within the project. If they do, we’ll use the existing model instead of generating an entirely new model. If the model doesn’t exist, we’ll train a new model that will be saved to those same files. While training this new model, we’ll configure it to produce output every 2 passes through the training data (“epochs” in machine learning terminology).
WEIGHTS_PATH = os.path.join(os.path.dirname(__file__), 'textgenrnn_weights.hdf5')
VOCAB_PATH = os.path.join(os.path.dirname(__file__), 'textgenrnn_vocab.json')
CONFIG_PATH = os.path.join(os.path.dirname(__file__), 'textgenrnn_config.json')
if not os.path.exists(WEIGHTS_PATH) or not os.path.exists(VOCAB_PATH) or not os.path.exists(CONFIG_PATH):
textgen = textgenrnn()
# train for 10 full passes over the training data ("epochs")
# and generate output every 2 epochs
textgen.train_on_texts(corpus, num_epochs=10, gen_epochs=2, new_model=True)
else:
textgen = textgenrnn(weights_path=WEIGHTS_PATH, vocab_path=VOCAB_PATH, config_path=CONFIG_PATH)
Finally, we’ve reached a point in our script where the textgen model is guaranteed to exist and be trained, so we’ll get the script to produce an output:
generated_item_description = textgen.generate(temperature=0.2)
print(generated_item_description)
Note that the generate function takes a temperature parameter. The temperature incentivizes the model to introduce more variance into the generated output. In general, increasing the temperature leads to more unpredictable output. This parameter can accept any value between 0 and 1, but for now, I have arbitrarily set the temperature to 0.2 (since we don’t know what the output of the fully-trained model will look like).
Without further ado, let’s train the model and see what happens.
Results and Analysis
I’ve selected some of my favorite outputs from the model to display below. I’ve also used my Dark Souls image generator to turn these outputs into more authentic images. For each image, I chose existing item icons that fit well with the generated text.



After only four epochs, the model was able to pick up on names and vocabulary used in Dark Souls, like Gwyn and the Dark Sun. The model also mentions “Weapon type” and “Attack type” when describing weapons, indicating that it recognizes these fields as important to the description’s format.
The model seemed to overfit quickly, meaning that generated text adhered too closely to the training corpus. With the temperature left at our arbitrarily-chosen value of 0.2, the model would output an entire item description verbatim from the game. The temperature needed to be substantially increased to introduce more variation into the generation process.
Final Thoughts
Although this implementation of a machine learning algorithm was not sophisticated enough to generate the evocative, esoteric qualities that embody Dark Souls item text, the algorithm did catch certain idiosyncrasies in the training text, and reused those idiosyncracies in its output. These qualities include various pieces of prominent vocabulary from the game, as well as the formatting structure that was repeated across weapon descriptions.
It’s worth noting that these machine-generated sentences are not intended as a replacement for human writing. Instead, the goal in this kind of endeavor is generally to amuse the viewer with a curated selection of the model’s outputs; to that end, I hope you enjoyed reading about this small experiment as much as I enjoyed putting it together!
Acknowledgements
- HotPocketRemix (for creating UnpackDarkSoulsForModding)
- Meowmaritus (for creating TextVessel)
- Max Woolf (for creating textgenrnn)
- Laura McLean (for proofreading and editing)